
Math Corner: Copyright in the Library of Babel
Or why every story has already been written.


Above is an illustration taken from “The Library of Babel”, a book written by Jorge Luis Borges in 1941. The book describes an apparently infinite library, filled with all the information that ever has, ever will, or indeed ever can be produced. Every grandmother’s re-telling of “Little Red Riding Hood”, the full equations of quantum gravity, and every sequel for “Game of Thrones” exists in the library, with one caveat.
You have to find them first.
The reason the library contains all knowledge is simple: It contains every possible combination of English letters and punctuation. Every true sentence exists in the library, as does every lie. But the vast majority of library is neither true nor false, because it is in fact nonsense.
With a library like this, the task of finding what you’re looking for is quite daunting. The infinite books are not categorized neatly by subject, as they were written quite thoughtlessly, and organized with similar thoughtlessness. Because of this thoughtlessness, you would spend more time finding even a nugget of intelligence in the library than you would if you had endeavored to simply write something yourself!
How bad is the situation? We’ll have to do some math to find out.
But first, a little philosophy.
Between Noise and Music is A Cipher
In today’s world, most information is compressed.
What is compression? It’s essentially a cipher that lets you write a shorter message with the same content. For a simple example, let’s look at a simple “a-cipher”.
Message: aaaaabaaacaaaaaaaaaaaaad
Can you think of a way to shorten the above message? Fundamentally, any compression algorithm is about finding helpful patterns in a message, and then converting that pattern into a shorthand. You’ve probably noticed that this message includes clusters of “a”, so our a-cipher encodes the message like this:
Compressed Message: 5b3c13d
The first message was 24 characters, but we’ve gotten it down to 7! The rule used in a-cipher converts any series of “a” into numbers representing the length of the series. You might be wondering “what if I want to write a number?”
You can’t! Our compression algorithm isn’t very good, but if English resembled our random message, then the cipher would boast a compression efficiency of 3.4.
But why are we talking about compression? What’s interesting about it (besides being the backbone of modern society’s data storage)?
The message is only meaningful in the context of the compression algorithm.
Look at this next compression.
Compressed Message: 2 b 0r n0t 2 b
What do you see? The a-cipher would give “aa b r nt aa b”, but I bet you see something else. Internally, your “hamlet-cipher” uses rules about phonetics and shape resemblance to convert “2” to “to” and “0” to “o”. That gets you the original message.
Message: to be or not to be
For any two messages, there is a cipher of some complexity that translates the first to the second. The difference in complexity between first message and the second is necessarily made up for by the cipher.
Without the cipher, the compressed message is meaningless. Conversely, with the right cipher, even white noise can be converted into meaningful text.
With the right cipher, we could even have every book in the world.
The Babel Cipher
You are potentially wondering what compression algorithms have to do with the Library of Babel. The answer is everything. And also a workaround for copyright laws.
The original Library of Babel is essentially a noisy signal. Without any pattern in its indexing, the library is utterly impenetrable, and without the correct knowledge, you might not even know it should you happen across some profound truth. Imagine stumbling onto a formula for deriving all prime numbers, and dismissing it as nonsense because the math is a millennium ahead of your own time!
Borges himself insisted the library was meaningful, so long as the correct language was used to describe it. The stories of a hundred unborn mythologies, unknown ethics, the most grotesque forms of smut, ignored by eyes blind to their meaning.
In reality, most readers entering the library are armed only with their single language and experience. To them, the library is as dark and intimidating as the illustration above, a black hole of meaning where totality converges with nothingness.
But what if the library had an index?
Enter the real Library of Babel. Created by Jonathan Basile, the Library is part compression algorithm, part database. Unlike the original conception, with its randomly placed books, the digital Babel is generated by formula. It is searchable. With a caveat.
So long as you know what you’re looking for already, you can find its index in the library. For instance, the full Hamlet speech, as written on Wikipedia, exists in the library on page 88 of the book “nayhirgmjbqld” in the 11th Volume on Wall 4 of Hexagon… well the address is quite large actually. Indeed, the address is almost as large as the speech!
The library contains every possible page of an English letter book, though not necessarily in the right order. By extension, every English letter book has, in a sense, been written in the library. By recording 1100 such indices, you could store the entirety of “The Lord of the Rings” trilogy!
This is the “Babel Cipher”. Any book can theoretically be recreated with Library of Babel indices. And feel free to share! Claiming copyright on the indices would be as ridiculous!
After all, you’re only borrowing books from the library.
Originality in Babel
The issue of copyright in the library, though not especially practical, is wider than it initially seems. As we said earlier, any message can be converted to any other message with the appropriate cipher.
By extension, not only books exist in the library. Each page in the Library of Babel contains 1,312,000 characters, aka a little over one megabyte of information. With the right converter, every possible image likely exists somewhere in the library, and by extension entire movies exist somewhere inside. Somewhere in the library even you yourself exist, catalogued at every point of your life along some set of indices.
This all begs the ancient question: is knowledge creation or discovery? Are we all searching the Library? Yes and no.
The English language pre-contains every possible English thought. But before the words “electricity”, “Jabberwock”, and “swagger” were minted, the thoughts formed from them did not exist in 26 characters. The cipher was insufficient, and lightning did not exist in Babel. In that sense, the truest form of creativity is found in William Gilbert, Lewis Carroll, and William Shakespeare: the making of words.
The real lesson here then is not about compression or copyright or libraries. It is about nonsense.
Embrace nonsense! Make up words! Name things as you like! In the making of the world, this was Adam’s first right! Only by giving meaning to noise do we fill Babel with books to find.
The Math of Babel
Enough philosophy. It’s math time.
There are, according to WolframAlpha, about 5.1 letters in the average English word. Merriam-Webster claims that there are approximately a million words in English (more on that claim later). The alphabet contains a humble 26 letters. How should we quantify the chances of getting a meaningful word by randomly printing 5 characters?
Shorter words somewhat complicate the issue. If we count syntax markers like “a” as meaningful, then we’ll be encountering meaning all the time! Longer words present an issue as well, as the they are exponentially less likely to be observed with each passing letter.
For complicated problem, there is always a dirty solution, and a correct solution. Here, we’ll show both, though before reading on, take a moment mull it over. How would you approach this?
Quick and Dirty
We can approximate the solution quickly by establishing some rules.
We make combinations of 5 characters, repetitions allowed
The characters can be any of the 26 English letters, or a blank space
We count a combination as an English word match if the combination matches the first 5 letters of a word
For words shorter than 5 characters, the combination must match the full word from the beginning of the line, and the extra should be blank spaces
Those four rules obtain a definition of a match that accounts for words over and under 5 characters. Sort of.
English has a lot of words like “ground” and “groundhog”. This means the space of unique “5 letter beginnings” is actually smaller than the million words we’re trying to guess the incidence of, and we should be reducing the chances accordingly.
But that’s more or less impossible, so we’ll add a fifth rule to complete our approximation:
All duplicate 5-letter starts have a letter replaced until they are unique
Now we can say there are a million possible matches in a mathematically rigorous way!
You are maybe complaining at this point. “This isn’t quick.” Fair. But even for dirty methods we must be precise in how we’re being dirty. We have defined a match, and we are showing all our shortcuts. This is an approximate, and therefore wrong, answer, but we have outlined how we’re wrong.
But I digress. There are a million possible matches. How many possible combinations are there?
Quite easy. For each of the 5 characters in our combination, there are 27 (letters or a blank space) branching paths. The number of possibilities multiplies by 27 with every step.
So there are 27^5, or 11,881,376, possible combinations of the 27 characters. There are about 11.88 times more combinations than words in 5 characters. an 8.4% chance of seeing a recognizable beginning of a word.
Oxford University says the average sentence length is 15 words on the lower side, so the chances of reading an average “English” sentence is equal to the chances of playing this game 15 times and only ever getting real words. “And” means repeated multiplications again, so chances are about 0.084^15, or 7.3e-15% (0.0000000000000000073).
To be clear, that’s any combination of English words. “cat umbrella ice their a mat pat an vape stick stick sick dig dog check” would count. The chances of getting a sensical sentence are actually much lower.
This is all to say, the difference in density between meaning and nonsense is astronomical in Babel.
But perhaps you feel that I’ve cheated. Taken too many shortcuts. “You said this is a Math Corner!” I hear you shouting.
Well, let’s do it the painful way.
The Painful Way
To do this right, we need incidences of word lengths.
So we turn to the “Journal of Statistical Planning and Inference”, Volume 14, Issues 2-3, “The distribution of English dictionary word lengths” by Lord Rothschild. Published in 1986, word length was slightly longer at a mean of 6.94 letters, but this was before the introduction of literary novelties such as “gat” and “fleek” (though “skibidy” helps push length up again).
It will have to do. They sampled 2477 words to produce their estimates, and we’re going to go with their distribution, while sticking to our supposed one million words.
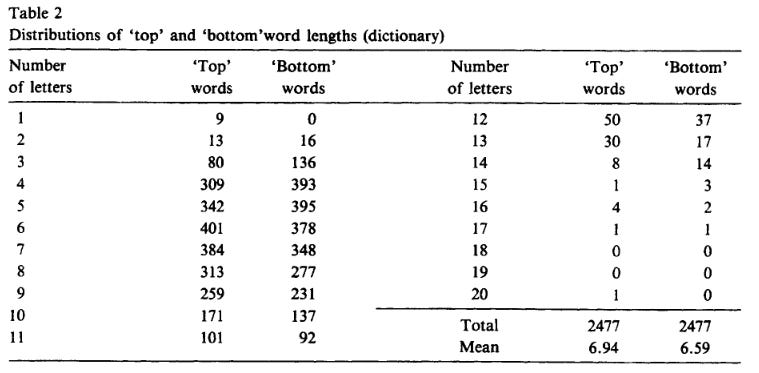
Total is 2477, and we’ll use the “Top” words column (top of a dictionary page sampled) since it shows counts for lower length words. The “proportion” of the English language each word category takes up is equal to the ”Top” count divided by the total. When we multiply the proportion by one million, we can obtain the approximate count of words per length.
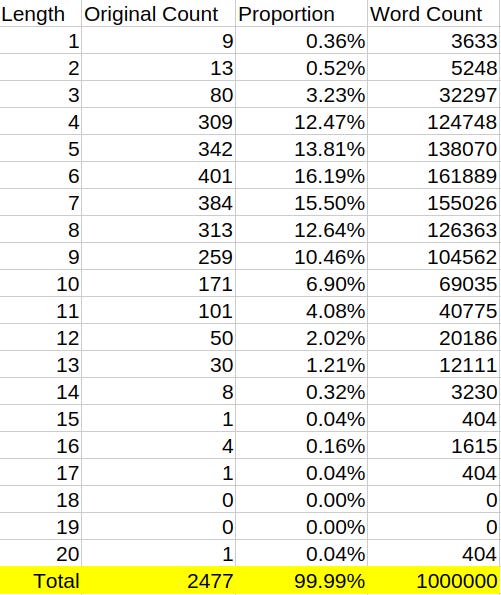
Immediately, we see a problem. There are apparently over three thousand single letter words. There are only 26 single letters. It is apparent that the author’s single counting strategy is, to put it lightly, flawed. There are also 2 many 2 letter words, seeing as there’s only 676 two letter combinations. Even the three letter combinations are clearly over-counted.
What gives? Well, for one, many of these words are duplicates (“bat” and “bat”). There’s probably some sampling bias that is over-representing low length words.
It would seem the million words claim is greatly over-exaggerated. Regardless, we’re going to need to fill in the numbers ourselves. With Scrabble.
Scrabble is a great resource here, because unlike the dictionary they are counting unique words. According Scrabble says there are 12,915 five letter words, 5,663 four letter words, 1,351 three letter words, and 107 two letter words. According to this list of one letter words in many languages, which is fun in its own right, there are only 2 one letter words, “a” and “I”. I think I must concur.
We’ll use those numbers to calculate proportional probabilities. A valid concern here is that we are only using up to 5 letters, but soon you’ll see that this is more than enough for our purposes.
For each word, the chances of randomly obtaining it is equal to:
P=1/(C+S)^L=1/(26+3)^L=1/29^L
Where P is the probability of obtaining a word by randomly drawing from the character pool, C is the number of English characters, S is the number of special punctuation characters (spaces, commas, and periods per the digital Babel), and L is the word length.
When we have single word probability, we can multiply by the total number of words for a given length category to obtain the probability for drawing any word of that length, the adjusted probability.
But what is the cumulative probability for words of any length? Let’s outline some assumptions:
We draw characters one at a time from the set of 29.
If we obtain a word, we stop.
So we cannot simply add the adjusted probabilities of all lengths. For each length, we must add the adjusted probability times the probability of not obtaining a prior, shorter word. The series formula looks like this:
C{L} = C{L-1} + A{L}*(1-C{L-1}); C{1} = A{1}
Where C is the cumulative probability, L is the length, and A is the adjusted probability. Note, we are still making simplifying assumptions here; for one, we are assuming (falsely) that our shorter words do not prefix longer words, which would decrease their effective count.
While we’re at it, we should really also calculate a “Real Word” probability that doesn’t count one and two letter words. After all, you aren’t going get much meaning from a series of “at’s” outside of social media.

So we get two new estimates! One says you have nearly a one in four chance of encountering a word! Though, it will probably be something like “it”. Your chance for encountering a word that means something is closer to 6.4%, which isn’t too far off our dirty estimate of 8.4%.
Notice that the cumulative probability barely changes between 4 and 5. There could be many, many six, seven, and eight letter words, but the nonsense increases exponentially by a factor of 29 with every letter. We don’t need the count of six letter words for this reason; it’s simply too small to really matter.
But let’s end on a happy note. “To be or not to be”. That’s mostly two letter words, and it’s considered quite profound! Six words in length, though really, we need spaces between the words so we’ll treat them like 3 letter words. What are our chances of grabbing the next Hamlet out of Babel?
6.4% chance of a word, 6 times in a row.
0.00000687%
I guess I like those odds.